Last week I published some open data publishing principles that can inform further development of the Data Discovery Alpha. This week I’ve begun turning those principles into actionable recommendations.
For example, if we want reuse rights to be clear then how do can licensing be published in both human and machine-readable formats? This is something I’ve previously explored quite extensively at the Open Data Institute (ODI), so there’s plenty of practical guidance to build on.
Similarly, if we want datasets to be discoverable, always be presented in context and legible to users, then what information and metadata might need to be presented?
I’ve begun the process of developing this guidance by:
- exploring the metadata already collected and managed by the ONS, and some of the ongoing work to improve it
- reviewing existing metadata vocabularies to determine how well they align with the needs of the ONS and its reusers
- comparing the metadata recommended by tools like open data certificates and some standard metadata profiles
You can see my brief comparison of open data certificates, Data on the Web Best Practices and some EU metadata profiles. There’s a great deal of agreement in terms of recommended metadata but there are some differences in what is considered to be mandatory.
The 3 main metadata vocabularies that I’ve been looking at are:
- Data Catalog Vocabulary (DCAT) — which is supported by data.gov.uk, data.gov, all of the major open data portals and a variety of other open data tools. DCAT is based on standard vocabularies like Dublin Core that have been in use for many years.
- DCAT-AP — an extension to DCAT that recommends the use of some additional metadata elements to ensure that data can be discovered and reused across different data portals in the EU
- STAT-DCAT — an extension of DCAT-AP that adds support for describing statistical datasets. This work has been lead by Eurostat and others in the statistical open data community
Collectively these standards describe how to:
- publish descriptions of datasets and their distributions (downloads)
- publish the structure of statistical datasets, for example, information on the dimensions and attributes used to report on observations
- relate datasets to supporting documentation, version notes, and other material relevant to reusers
This is exactly what we need in order to present data in context and to ensure that users can understand how the data is structured.
A variety of formats can be used to publish this metadata, but JSON-LD looks like a strong candidate for a common, baseline format.
To start testing out how well this works in practice I’ve started putting together some examples.
The examples include exploring Google’s recently launched support for describing datasets using Schema.org. This is at an early stage but is very closely aligned to existing standards and formats.
Collectively this looks like a promising way forward, and should provide a solid foundation for implementing the open data publishing principles.
The next steps are to test this out with more examples, particularly around describing statistical datasets. I’m also keen to explore how CSV on the Web can be used to help provide metadata for the CSV files published by the ONS.
As ever, if you have feedback or comments then please get in touch.


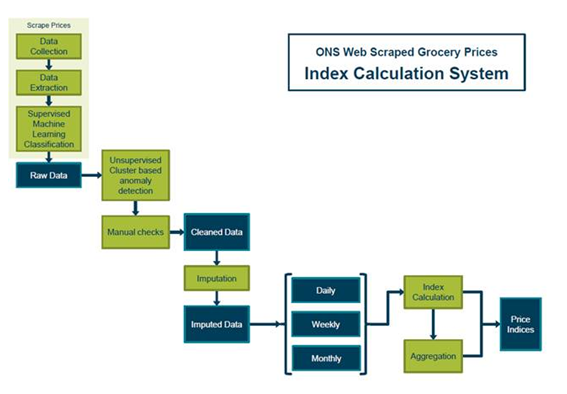
 The growth of online retailing over recent years means that price information for many goods and services can now be found online. Web scrapers are software tools for extracting these data from web pages. The Big Data Team has developed prototype web scrapers for three online supermarket chains: Tesco, Sainsbury and Waitrose, which have been running since June 2014. These scrapers were programmed in Python using the
The growth of online retailing over recent years means that price information for many goods and services can now be found online. Web scrapers are software tools for extracting these data from web pages. The Big Data Team has developed prototype web scrapers for three online supermarket chains: Tesco, Sainsbury and Waitrose, which have been running since June 2014. These scrapers were programmed in Python using the